بینایی ماشین چیست (به روزرسانی 2020)

بینایی ماشین یکی از داغترین مباحث هوش مصنوعی و علوم کامپیوتر است که تاکنون نتوانسته با قدرت چشمان انسان برابری داشته باشد.

بینایی ماشین به کامپیوتر آموزش میدهد تا دنیای واقعی بصری را تفسیر کرده و درک کند. کامپیوترها با استفاده از تصاویر دیجیتالی از دوربینها، ویدیوها و مدلهای شبکه عصبی عمیق میتوانند افراد و یا اشیا را به طور دقیق شناسایی کرده و سپس به چیزی که میبینند عکس العمل نشان دهند.
[fusion_code]PHN0eWxlPi5oX2lmcmFtZS1hcGFyYXRfZW1iZWRfZnJhbWV7cG9zaXRpb246cmVsYXRpdmU7fS5oX2lmcmFtZS1hcGFyYXRfZW1iZWRfZnJhbWUgLnJhdGlve2Rpc3BsYXk6YmxvY2s7d2lkdGg6MTAwJTtoZWlnaHQ6YXV0bzt9LmhfaWZyYW1lLWFwYXJhdF9lbWJlZF9mcmFtZSBpZnJhbWV7cG9zaXRpb246YWJzb2x1dGU7dG9wOjA7bGVmdDowO3dpZHRoOjEwMCU7aGVpZ2h0OjEwMCU7fTwvc3R5bGU+PGRpdiBjbGFzcz0iaF9pZnJhbWUtYXBhcmF0X2VtYmVkX2ZyYW1lIj48c3BhbiBzdHlsZT0iZGlzcGxheTogYmxvY2s7cGFkZGluZy10b3A6IDU3JSI+PC9zcGFuPjxpZnJhbWUgc3JjPSJodHRwczovL3d3dy5hcGFyYXQuY29tL3ZpZGVvL3ZpZGVvL2VtYmVkL3ZpZGVvaGFzaC9pWXJ1bi92dC9mcmFtZSIgYWxsb3dGdWxsU2NyZWVuPSJ0cnVlIiB3ZWJraXRhbGxvd2Z1bGxzY3JlZW49InRydWUiIG1vemFsbG93ZnVsbHNjcmVlbj0idHJ1ZSI+PC9pZnJhbWU+PC9kaXY+[/fusion_code]تاریخچه بینایی ماشین:
مطالعات اولیه در حوزه بینایی ماشین در دهه ۱۹۵۰ اتفاق افتاده است. در این مطالعات از مدلهای اولیه شبکه عصبی برای تشخیص لبههای اشیا و یا دستهبندی اشیا به دستههای مختلف مانند مربع و دایره استفاده شده است. در دهه ۱۹۷۰ برای اولین بار از بینایی ماشین به صورت تجاری استفاده شد که نوشتههای دستنویس و یا تایپ شده را با استفاده از شناسایی حروف نوری از یکدیگر تشخیص میداد و این شیوه برای تفسیر متون نوشته شده برای افراد نابینا به کار گرفته شد.
زمانی که اینترنت در دهه ۱۹۹۰ توسعه یافت، مجموعههای بزرگی از تصاویر آنلاین برای تحلیل تولید میشد و در نتیجه برنامههای تشخیص چهره ظهور یافتند. این دادههای رو به رشد، این امکان را به کامپیوترها داد تا بتوانند افراد خاص را در تصاویر و ویدیوها تشخیص دهند.
امروزه ابزارهای زیادی در حوزه بینایی ماشین انقلابی را به پا کرده اند:

تکنولوژی گوشیهای هوشمند با دوربینهای تعبیه شده در آنها، دنیای مجازی را با تصاویر و ویدیوهای خود پُر کردهاند.

قدرت محاسباتی رایانهها بسیار رشد یافته و در دسترس همگان قرار گرفته است.

سخت افزارهایی که در حوزه بینایی ماشین و تحلیل آنها استفاده میشوند به صورت بسیار گستردهای در دسترس هستند.

الگوریتمهای جدید مانند شبکههای عصبی عمیق (Deep neural network) میتوانند از توانمندیهای نرم افزاری و سخت افزاری جدید به خوبی استفاده کنند.
تاثیری که این پیشرفتها بر حوزه بینایی ماشین داشته، بسیار شگرف است. دقت تشخیص اشیا و کلاسبندی آنها تنها در کمتر از یک دهه از ۵۰ درصد به ۹۹ درصد افزایش یافته است، و سیستمهای امروزی بسیار دقیقتر از انسانها میتوانند ورودیهای بصری را تشخیص داده و به آنها عکس العمل نشان دهند.

شباهت بینایی ماشین و پازل:
تا به حال به چگونگی حل یک پازل فکر کردهاید؟
شما تمامی تکههای پازل را دارید و باید آنها را در کنار هم قرار دهید تا بتوانید یک تصویر را ایجاد کنید.
کامپیوترها نیز تصاویر بصری را مشابه یک پازل کنار هم قرار میدهند و این همان روندی است که شبکههای عصبی برای بینایی ماشین انجام میدهند. آنها تکههای مختلف تصویر را تشخیص میدهند، لبههای آنها را شناسایی میکنند و سپس مولفههای آنها را مدلسازی میکنند. آنها با فیلتر کردن و مجموعهای از اقدامات با استفاده از لایههای شبکههای عصبی عمیق میتوانند تکههای یک تصویر را کنار هم قرار دهند و این همان کاری است که ما در هنگام حل پازل انجام میدهیم.
همچنین کامپیوترها هرگز تصویر نهایی را ندارند و نمیدانند که خروجی پازل چه چیزی خواهد بود بلکه آنها یاد میگیرند تا با استفاده از صدها و هزارها تصاویر مرتبط بتوانند خروجی مورد نظر را تشخیص دهند.
همچنین فرآیند آموزش کامپیوترها به این صورت است که برنامهنویس میلیونها عکس از شی مشخص را آپلود کرده و در اختیار کامپیوتر قرار میدهد تا خود کامپیوتر ویژگیهای تعیینکننده آن شی را یاد بگیرد.
برای مثال برای تشخیص یک گربه به جای آموزش اعضای بدن یک گربه به کامپیوتر، میلیونها عکس گربه به کامپیوتر داده میشود و خود کامپیوتر ویژگیهای متفاوت گربهها را فرا میگیرد و در نتیجه میتواند یک گربه را در یک تصویر یا ویدیو تشخیص بدهد.
انقلاب یادگیری عمیق در بینایی ماشین:
در دهه ۱۹۸۰ یک دانشمند فرانسوی شبکههای عصبی پیچشی یا (convolutional neural network CNN) را معرفی کرد. این نوع شبکه عصبی شامل چندین لایه از نورونهای مصنوعی میشود که این نورونها در واقع مولفههای ریاضیاتی هستند که تا حدودی از نورونهای بیولوژیکی تقلید میکنند. زمانی که یک شبکه عصبی پیچشی تصویری را پردازش میکند، هر یک از لایههای آن ویژگیهای معینی از پیکسلها را استخراج میکند. اولین لایه موارد ساده را تشخیص میدهد (مانند لبههای افقی یا عمودی) و همینطور که به لایههای درونیتر شبکه عصبی نزدیک میشویم لایههای شبکه، ویژگیهای پیچیدهتری را تشخیص میدهند (مانند گوشهها و اشکال). لایههای نهایی شبکه عصبی موارد بسیار جزیی مانند چهرهها، دوچرخه، ماشین و … را شناسایی میکنند. خروجی لایههای شبکه عصبی جدولی از مقادیر عددی میباشد که نشاندهنده احتمال شناسایی یک شی مشخص در تصویر را بیان میکند.

این نوع از شبکههای عصبی بسیار هوشمند و کارآمد بودند اما یک ایراد بسیار بزرگ داشتند:
تنظیم و استفاده از آنها نیاز به حجم زیادی از دادهها و منابع محاسباتی داشت که ممکن است در زمان مورد نظر در دسترس نباشند. در نتیجه این شبکه عصبی تنها توانست در حوزه تجاری محدود به بانکها و سرویسهای پست شد، که تنها باید حروف دست نویس و حروف موجود بر روی نامهها و چکها را پردازش میکرد. اما در حوزه تشخیص اشیا، نتوانست قابلیت خوبی از خود نشان دهد و در نتیجه جای خود را به روشهای یادگیری ماشین داد.
در سال ۲۰۱۲، دانشمندان هوش مصنوعی از تورنتو نوع جدیدی از شبکههای عصبی پیچشی را ایجاد کردند که در مسابقات شناسایی تصویر یا ImageNet نیز برنده شد. این پیروزی سبب شد که ذهنها به سمت بازبینی شبکههای عصبی پیچشی سوق بیابد. این واقعه شبکههای عصبی پیچشی را احیا کرد و انقلابی در یادگیری عمیق ایجاد نمود (یادگیری عمیق شاخهای از یادگیری ماشین است که شامل لایههای متعددی از شبکههای عصبی مصنوعی میباشد). پس از پیشرفتهای شبکههای عصبی پیچشی و یادگیری عمیق، بینایی ماشین توانست رشد بسیار چشم گیری را تجربه کند.
بینایی ماشین چگونه کار می کند؟
بینایی ماشین در سه سطح زیر انجام میشود:
به دست آوردن یک تصویر:

تصاویر مختلف (حتی با مجموعه دادههای بسیار زیاد) میتوانند از طریق ویدیوها، عکسها یا تکنولوژیهای سه بعدیِ تحلیلی جمعآوری شوند.
پردازش تصاویر:

مدلهای یادگیری عمیق، قسمت بزرگی از فرآیند پردازش تصویر را به صورت اتوماتیک انجام میدهد، گرچه این مدلها اغلب با استفاده از هزاران تصویر از پیش تعریف شده و برچسب گذاری شده آموزش داده شدهاند.
درک تصویر:

آخرین گام، مرحله تفسیر است که در آن شی مورد نظر تشخیص داده میشود و یا کلاسبندی مورد نظر انجام میگیرد.
امروزه سیستمهای هوش مصنوعی میتوانند فراتر رفته و بر مبنای تصاویرِ ورودی، عکس العملهای بعدی خود را انتخاب کنند. شیوههای متفاوتی از بینایی ماشین وجود دارد که در زمینههای مختلفی قابل استفاده هستند:
قطعه بندی تصویر: یک تصویر به چندین ناحیه و یا تکههای مجزا تقسیم میشود تا هر یک از آنها به صورت جداگانه بررسی و آزمایش شوند.
تشخیص اشیا: شی مورد نظر را در یک تصویر شناسایی میکند. روشهای تشخیص اشیا در سطح پیچیدهتر میتوانند به آسانی چندین شی را در یک تصویر شناسایی کنند. برای مثال در یک بازی فوتبال میتوانند بازیکن حمله، بازیکن دفاع، توپ و … را تشخیص دهد.
تشخیص چهره: یکی از شیوههای پیشرفته تشخیص اشیا است که صرفا چهره انسانها (البته چهره یک شخص خاص) را در یک تصویر تشخیص میدهد.
تشخیص لبه: تکنیکی برای شناسایی لبههای بیرونی یک شی یا صحنه استفاده میشود و هدف از آن شناسایی بهتر اشیا داخل تصویر است.
تشخیص الگو: فرآیند تشخیص اشیا، رنگها و یا سایر علائم بصری تکراری در یک تصویر است.
کلاس بندی تصویر: تصاویر به دستههای مختلف تقسیم بندی میکند.
تطبیق ویژگی ها: یکی از انواع روشهای تشخیص الگو میباشد که شباهتهای میان تصاویر را با یکدیگر تطبیق میدهد تا بتواند آنها را دستهبندی نماید.
برنامههای بینایی ماشین در سطوح پایین ممکن است تنها یکی از این شیوهها را استفاده کنند، اما مدلهای پیچیدهتر (مانند بینایی ماشین برای ماشینهای خودران) نیازمند ترکیبی از چندین شیوه فوق برای رسیدن به اهدافشان هستند.
مدل بینایی ماشین:
اخیرا دانشمندان دانشگاه MIT یک مدل کامپیوتری تشخیص چهره ایجاد کردهاند، که مجموعهای از محاسبات را انجام میدهد تا بتواند مراحل برنامههای گرافیکی کامپیوتری را معکوس کند، و یک مدل یا بازنمایی دو بعدی از یک چهره را به دست بیاورد.
قابل ذکر است که مدلهای کامپیوتری پردازش چهره میتوانند چگونگی روند سریع مغز انسان برای تولید بازنماییهای پر از جزییاتِ بصری را آشکار کند.

زمانی که ما چشمان خود را باز میکنیم، ذهن ما جزییات محیط اطراف خود را به صورت دقیقی پردازش میکند.
اما چگونه مغز انسان قادر است چنین بازنمایی دقیقی از جهان داشته باشد؟
این سوالی است که در حوزه بینایی ماشین جزو یکی از مسائل پیچیده دنیای کامپیوتر محسوب میشود.
دانشمندانی که مغز انسان را مطالعه میکنند تلاش کردهاند تا این پدیده را با استفاده از مدلهای کامپیوتری تکرار نمایند، اما تاکنون، مدلهای مطرح دنیا تنها توانستهاند فعالیتهای ساده مغز را بازنمایی کنند (مانند برداشتن یک شی یا تشخیص یک چهره در میان پس زمینه شلوغ و پر از جزییات).
اما اکنون تیمی از محققین علوم شناختی دانشگاه MIT توانستهاند مدل کامپیوتری ایجاد کنند که توانایی سیستماتیکِ بینایی انسان برای تولید سریع توصیفی از صحنههای پیچیدهی یک تصویر را تقلید میکند، و مفاهیمی را در مورد چگونگی انجام این فرآیند توسط مغز انسان توضیح میدهد.
جاش تننبام، پروفسور علوم شناختی – محاسباتی و عضو آزمایشگاه علوم کامپیوتر و هوش مصنوعی دانشگاه MIT و مرکزِ مغز – ذهن – ماشین (Center for Brains, Minds, and Machines=CBMM) و یکی از نویسندگان این مقاله میگوید:
“هدفی که در این تحقیق به دنبال دستیابی به آن هستیم، توضیحی در مورد چگونگی دقیقتر شدن ادراک بینایی است، و میخواهیم این دقت را فراتر از اتصال برچسبهای معنایی بر روی قسمتهای مختلف تصویر ببریم. همچنین میخواهیم به این سوال پاسخ دهیم که انسانها چگونه میتوانند محیط فیزیکی اطراف خود را ببینند”.
در این مدلِ جدید فرض شده است که:
زمانی که مغز ورودی بصری را دریافت میکند، به سرعت مجموعهای از محاسبات را اجرا میکند، در واقع مراحل برنامههای گرافیکی کامپیوتری را معکوس میکند، تا یک مدل دو بعدی از یک چهره یا یک شی را به دست بیاورد.
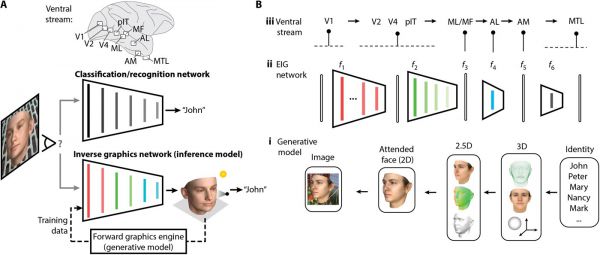
به این نوع از مدلهای کامپیوتری، گرافیک معکوس کارآمد یا (efficient inverse graphics EIG) گفته میشود، که میتواند به خوبی با رکوردهای دیجیتالی گرفته شده از نواحی تشخیص چهرۀ مغز پستاندارنِ شبیه انسان کار کند. محققین میگویند: “این امکان وجود دارد که سیستم بینایی این دسته از پستاندارن، مشابه مدلهای کامپیوتری عمل کند”.
گرافیک معکوس:
بعد از گذشت دهههای متوالی، تحقیقات دانشمندان بر روی سیستم بینایی مغز انسان به صورت دقیق مشخص کرده است که چگونه نورهای وارد شده به شبکیه تبدیل به صحنههای منسجم میشوند. این یافتهها به محققین هوش مصنوعی کمک کرده است تا بتوانند مدلهای کامپیوتری را ایجاد کنند که میتواند جنبههایی از این سیستم را تقلید کند (مانند تشخیص چهره یا سایر اشیا).
تننبام عنوان کرده است که:
“بینایی یکی از جنبههای کاربردی مغز انسان است که ما به بهترین نحو ممکن آن را در انسانها و حیوانات درک کردهایم، و تاکنون بینایی ماشین یکی از موفقترین حوزههای هوش مصنوعی بوده است. امروزه ماشینها میتوانند به عکسها نگاه کرده، تشخیص چهرهها را به راحتی انجام دهند و سایر اشیا را نیز میتوانند شناسایی کنند. اما با این حال این سیستمهای پیشرفته کامپیوتری حتی نتوانستهاند به عملکرد سیستم بینایی انسان نزدیک شوند.”
ییکل یلدیریم، نویسنده اصلی این مقاله، استاد راهنمای دانشگاه Yale در ایالت آمریکا و دانشجوی سابق مقطع فوق دکتری در دانشگاه MIT میگوید:
“مغز ما انسانها به این گونه فعالیت نمیکند که فقط قرار گرفتن جسمی در محلی مشخص را تشخیص دهد و بر چسبی بر روی آن قرار دهد، بلکه ما تمامی اشکال، هندسه، سطوح و بافت جسم مورد نظر را میبینیم. در واقع ما دنیای بسیار غنی از یک شی را با نگاه کردن به آن به دست میآوریم“.
اما سوالی که همچنان باقی میماند این است که چگونه مغز میتواند این فرآیند، که با نام گرافیک معکوس شناخته میشود، را با این سرعت اجرا کند؟
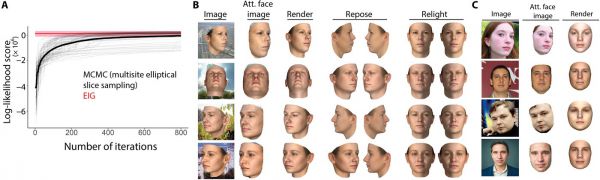
دانشمندان علوم کامپیوتر سعی کردهاند تا الگوریتمهای را ایجاد کنند که این فرآیند را شبیه سازی نماید، اما بهترین آنها نیازمند چرخههای تکراری زیادی هستند که اجرای آنها زمان خیلی زیادی در مقایسه با ذهن انسان طول میکشد (ذهن انسان تنها ۱۰۰ تا ۲۰۰ میلی ثانیه زمان نیاز دارد تا بتواند یک بازنمایی بسیار دقیق از اشکال دیده شده را در ذهن ایجاد کند).
دانشمندان علوم اعصاب بر این باور هستند که علت سرعت بالای ذهن انسان در پردازش تصاویر، عبور آنها از لایههای منظم و سلسله مراتبی نورونهای مغز میباشد.
در نتیجه اعضای این تیم تحقیقاتی تصمیم گرفتند تا نوع خاصی از شبکههای عصبی عمیق را ایجاد کنند تا بتوانند چگونگی سلسله مراتب نورونها در استنتاج ویژگیهای صحنه دیده شده را نشان دهند (که در این مقاله یک چهره خاص میباشد). بر خلاف شبکههای عصبی عمیقِ استاندارد که در بینایی ماشین از آنها استفاده میشود و بر اساس دادههای برچسب گذاری شده آموزش میبینند، این شبکه عصبی عمیق با استفاده از مدلی آموزش دیده میشود که نشان دهنده بازنماییهای داخلی ذهن از صحنههای دارای صورت اشخاص است.
در نتیجه مدل آنها یاد میگیرد تا گامهای برنامههای گرافیکی کامپیوتری در تولید تصاویر صورت را معکوس نماید. این برنامههای کامپیوتری با بازنمایی سه بعدی تصویر صورت شخص شروع به کار میکند و سپس آن را به تصویر دو بعدی تبدیل میکند که نشاندهنده دیدن صورت از یک زاویه خاص است. این تصاویر میتوانند بر روی پس زمینهای دلخواه قرار بگیرند. محققین این نظریه را عنوان میکنند که سیستم بینایی مغز انسان ممکن است که کاری مشابه همین فرایند را در هنگام تصور چهره یک شخص یا رویا دیدن انجام بدهد.
این محققین، شبکه عصبی عمیق خود را این گونه آموزش میدهند که مراحل زیر را به صورت معکوس اجرا کند:
– با یک تصویر دو بعدی شروع میکند.
– ویژگیهایی مانند بافت، انحنا و نورپردازی را اضافه میکند.
– و در نهایت بازنمایی ۵/۲ بعدی ایجاد میشود.
– این تصاویر ۵/۲ بعدی، شکل و رنگ چهره را از یک زاویه خاص مشخص میکند. سپس آنها به بازنمایی سه بعدی تبدیل میشوند که بستگی به زاویه دید ندارند.
محققان این مقاله کارایی مدل خود را با توانایی انسانها در یک فعالیت تشخیص چهره از زوایای متفاوت مقایسه و بررسی نمودند و به این نتیجه رسیدند که مدل ارائه شده شباهت بیشتری به سیستم بینایی انسان در مقایسه با مدلهای تشخیص چهره قبلی از خود نشان داده است.
تتنبام میگوید:
“اگر بتوانیم نشان دهیم که اینگونه از مدلها میتوانند چگونگی کارکرد مغز انسانها را نشان دهند، این مقاله به محققان بینایی ماشین کمک خواهد کرد تا این مسیر را جدیتر گرفته و منابع مهندسی بیشتری را در حوزه گرافیک معکوس سرمایه گذاری نمایند.
با تمامی این اوصاف مغز انسان همچنان تنها استاندارد طلایی برای تمامی ماشینها محسوب میشود که میتواند دنیای اطراف را به سرعت و دقت مشاهده نماید.”